
April 17 2026
By Chang Xu
Last year, Claude Code was the only terminal coding agent worth using. Today I swap between Opus and Codex constantly, asking them to collaborate on the same task. Opus is the creative risk-taker, Codex is the precise implementer. You want both, and you want them pushing each other.
But both lock you into their ecosystems. They also have to serve millions of users profitably. Behind the scenes, there are optimizations (caching strategies, effort routing, model selection, and I suspect quantization) that trade quality for margin in ways you do not see or control. I have written about the economics: my Claude Code logs showed $10,000/month in API-equivalent usage on a $100/month plan, although this was the good ol' days before the recent pricing changes.
When I started hitting usage limits, I made my setup portable so I could move between Claude Code and Codex with zero switching cost. That is when something clicked. Once you go multi-model, you start asking: which model is best for this specific task? The best model for planning. For context compaction. For code editing. For verification. The levers you want are the ones open source gives you.
The first generation of AI tools were prompts. You typed a question, you got an answer. The model was the product.
Agents are different. An agent is a system: a model embedded inside a harness that manages planning, tool use, context, memory, permissions, verification, and recovery. When you use Claude Code, the model is one component. The harness is the other. The harness matters enormously.
As agent harnesses mature, the work is decomposing into reusable primitives. Planning. Exploration. Context compaction. Code editing. Bash execution. Verification loops. Memory writeback. Error recovery. These primitives are stabilizing across every major harness. Claude Code, Codex, and the open-source alternatives all converge on roughly the same set of building blocks.
Once you see agents as systems of primitives, three things become obvious:
You want the best model per primitive, not the best model overall. A fine-tuned smaller model can outperform Opus at context compaction while running faster and costing less. A different model might be better at structured tool calls. Another at planning. The frontier model is still the best generalist, but agents do not need generalists for every step. They need specialists.
You want full control over prompts, context, and inference. In Claude Code, even when I create a subagent with custom system prompts, the harness loads its own system prompts and conversation history underneath. There is a significant amount of context in every LLM call that I do not control. With an open-source harness, I control the full context window. I can crystallize exactly the instructions the model needs and strip everything else.
You want the ability to fine-tune on your workflows. You cannot fine-tune Opus. You can fine-tune Qwen, MiniMax, GLM, or Kimi. If you have a specific codebase, a specific set of tools, a specific style of planning, you can train a model that is better for your work than any general-purpose frontier model. Cursor ships improved model checkpoints every five hours based on real-time reinforcement learning from user interactions. That tight feedback loop is only possible with models you can train.
This is where open source has a structural advantage. Not because of ideology, but because modular systems reward control.
Eighteen months ago, open-source models were a rounding error in production AI usage. Today they account for nearly half of all tokens flowing through the system. The shift has been fast, broad-based, and driven by real workloads, not GitHub stars or survey hype.
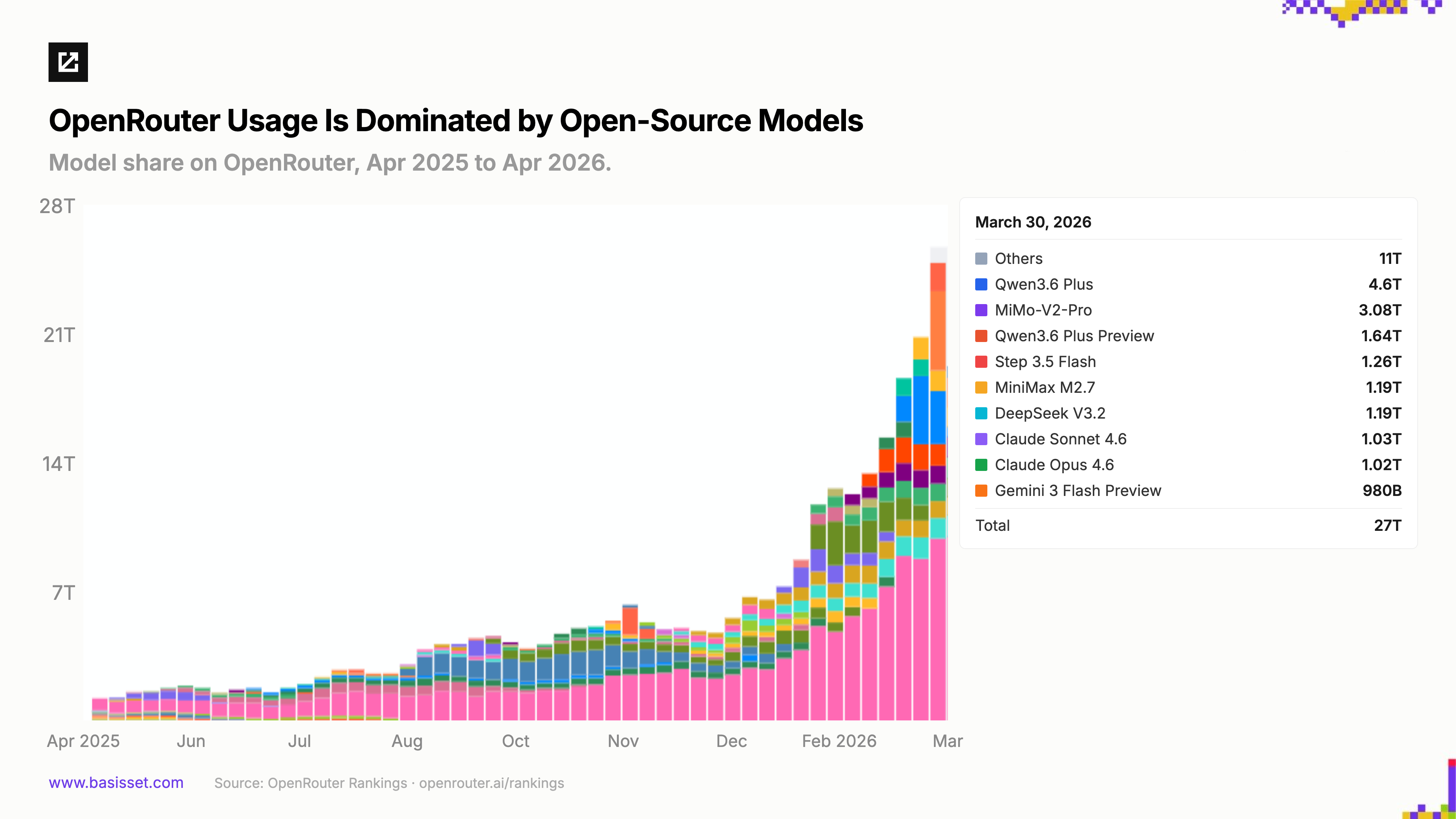
Open-source models are capturing real usage. One public proxy for production model usage is OpenRouter, which routes tokens across models and providers for developers and agent harnesses worldwide. It captures only a fraction of the total ecosystem, but likely the fraction most open to switching models. Its leaderboards tell a striking story: total throughput has grown roughly 5x over the past three months to 27 trillion tokens in a single week in March, and roughly 70% of volume today goes to open-source models. This is a structural recomposition of where inference happens.
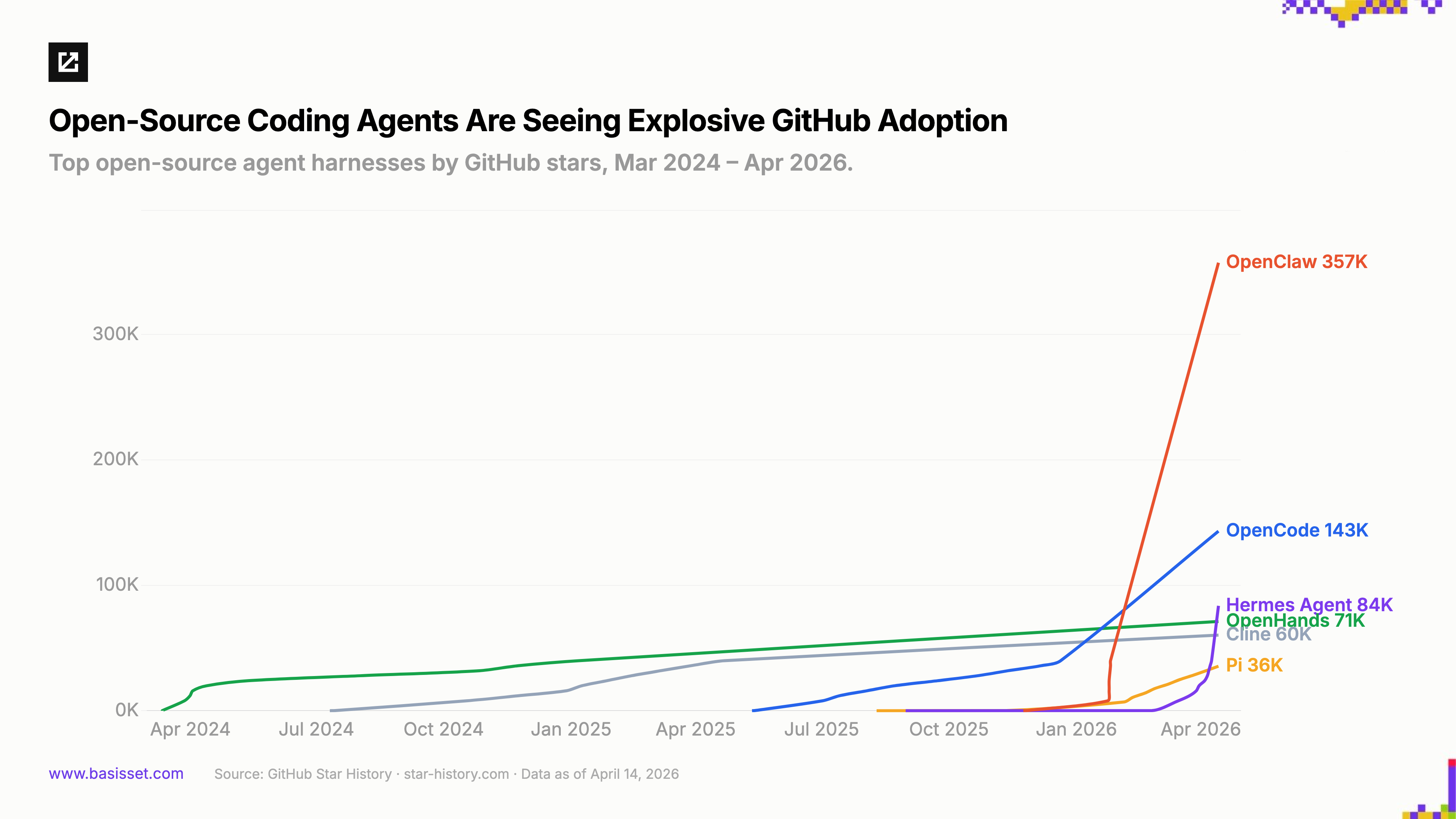
Open-source agent harnesses are seeing explosive adoption. The model layer is only half the story. The harness, the system that wraps a model with planning, tool use, memory, and recovery, is where developers exercise control. In under a year, the landscape went from a handful of early projects to a full-blown ecosystem.
The early entrants proved the model: OpenHands (71K stars, 464 contributors) and Cline (60K stars, 3.5M VS Code installs) showed community-driven coding agents could attract serious adoption. OpenCode (143K stars) raised the bar on customization, giving developers full control over system prompts and agent behaviors, and built a formidable marketing presence on X that accelerated its distribution.
Then adoption went vertical. OpenClaw launched in November 2025 and reached 357K stars in under five months, the fastest-growing project in GitHub history. Pi (35.5K stars) introduced selective conversation history editing and session branching. Hermes Agent from Nous Research rocketed to 84K stars in under two months with a self-improving agent that optimizes its own skills through evolutionary learning. Each harness unlocks a different control lever: prompt ownership, context management, multi-channel deployment, self-improvement. The common thread is control.
Local inference has become real infrastructure. Running models locally used to be a hobbyist exercise. In 2026 it is a production capability.
Ollama (167K stars, 114M Docker pulls) and llama.cpp (101K stars, 1,588 contributors) are the runtime foundations. Georgi Gerganov, the creator of llama.cpp, joined Hugging Face in February 2026 to make local inference "a meaningful alternative to cloud inference."
The infrastructure around local inference is filling in: exo (42K stars) clusters consumer devices into distributed inference networks, oMLX cuts time-to-first-token on Macs to under 5 seconds, and model compression keeps advancing (1-bit quantization, 6x KV cache reduction, Qwen3.5-27B on 16GB). The gap between cloud and laptop inference is closing quarter by quarter.
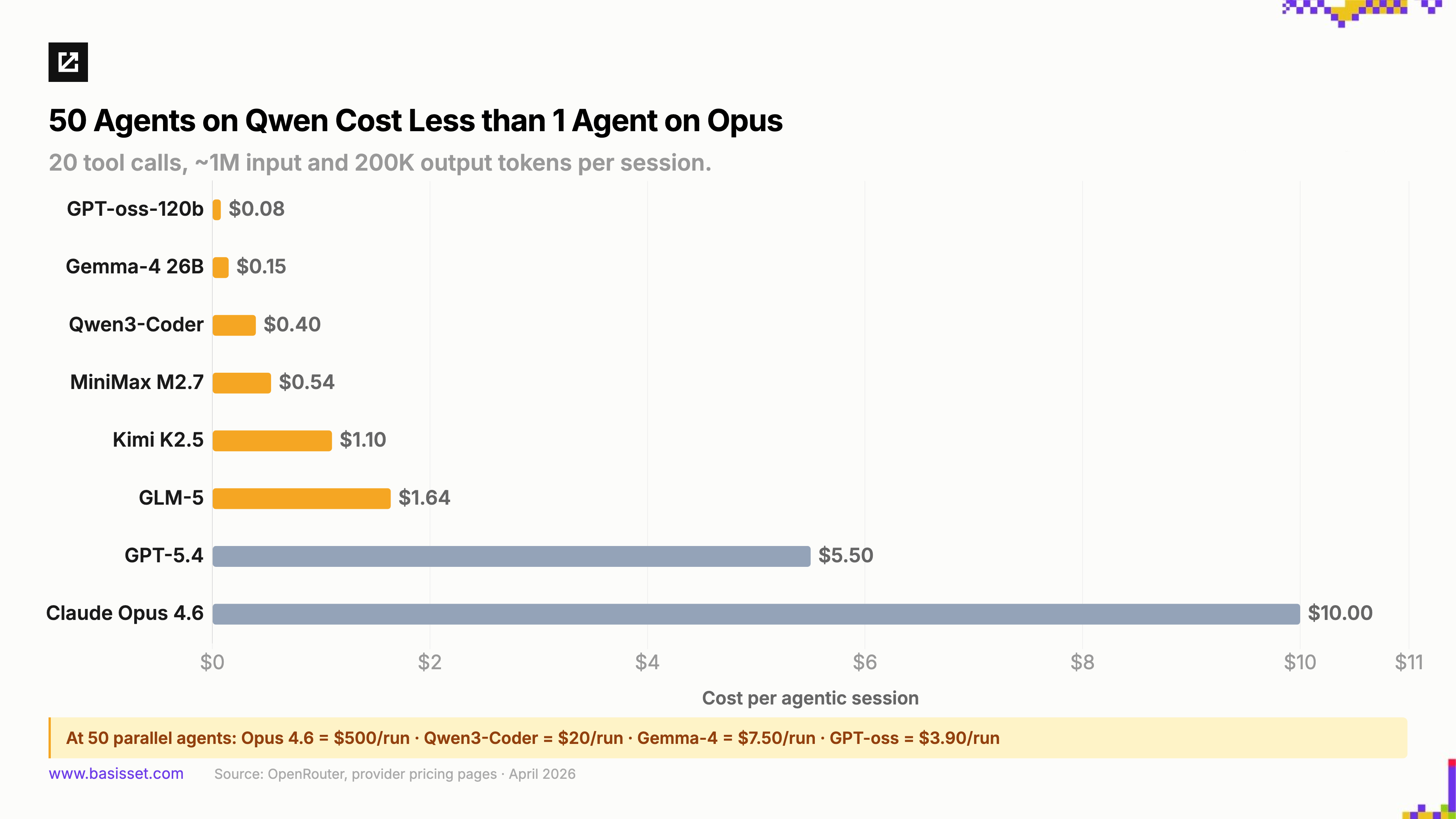
The cost gap is staggering, and agent workloads amplify it. A single chat session makes the price difference manageable. Fleets of agents making hundreds of sequential calls turn it into the defining constraint.
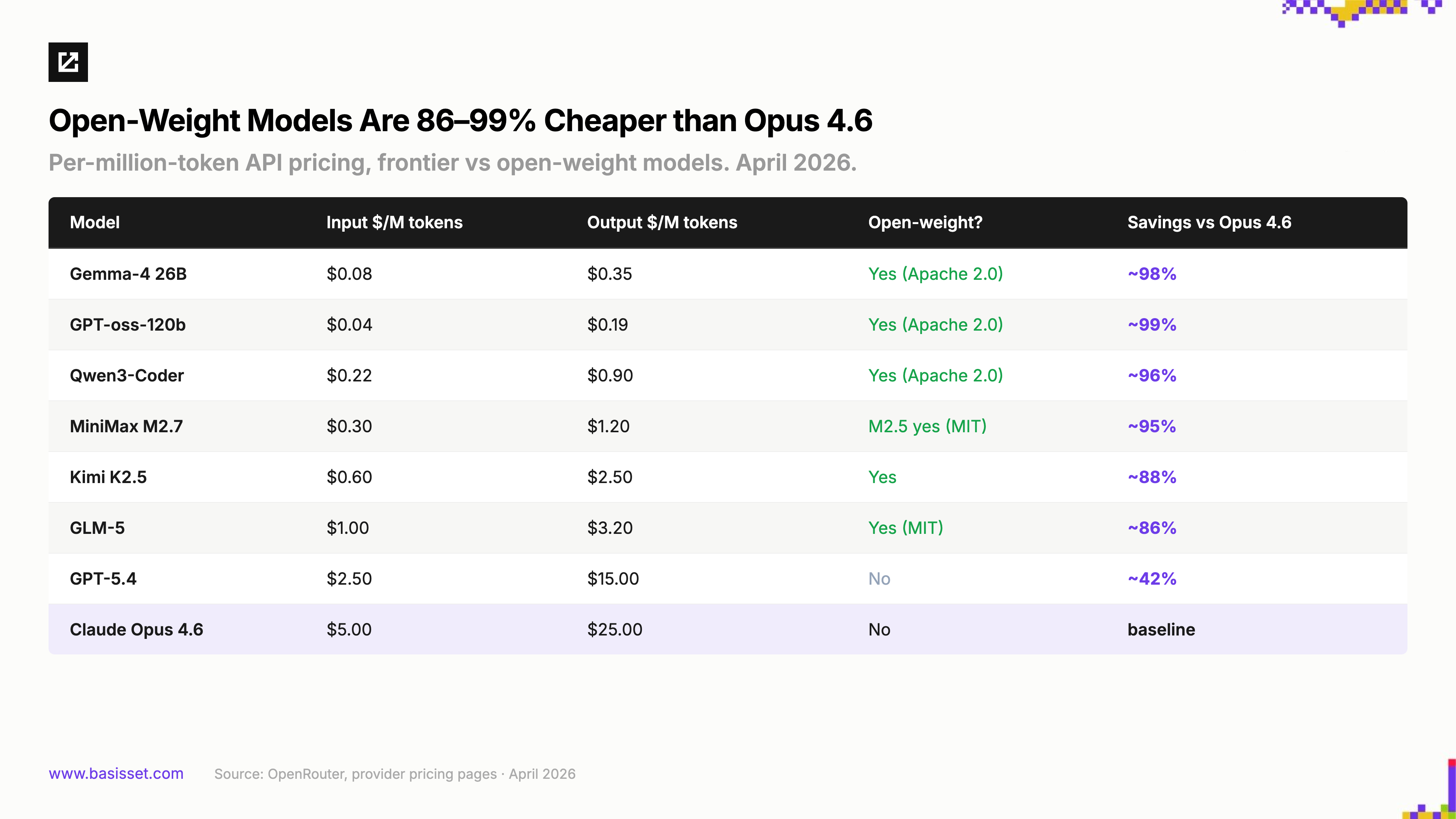
Run the math on a typical agentic session and the gap is 10-25x. Now multiply by fifty parallel agents running speculative execution paths, redundant verification loops, and always-on background tasks. The teams building those architectures are running open models, not because they want to, but because they could not afford frontier pricing at that scale. The smaller versions of many of these models can run locally for free if they fit on your hardware.
I am not betting against frontier models. I use Opus and GPT daily. They are extraordinary. Closed platforms have massive distribution: Claude Code and Codex have millions of users. Enterprise buyers prefer vendors they can call. For genuinely novel, hard problems, frontier models may always hold an edge. The market is enormous, and both open and closed source will thrive.
But I am betting that the agent era rewards systems over single models, and that systems reward control. The more agentic software becomes, the more valuable openness becomes, not because open source is ideologically pure, but because modular systems compound. Linux did not win because it was free. Kubernetes did not win because it was open. They won because composable systems attract more builders, more specialization, and more innovation than any single vendor can produce alone.
The same dynamic is playing out in agents. The models will keep getting better, open and closed. The harnesses will keep proliferating. The companies that help developers and enterprises exercise control over this increasingly complex stack, with memory, type safety, security, orchestration, and composability, are where we are placing our bets.
If you are building in this space, we would love to hear what you are working on. In our next post, we'll dive into areas that we find exciting to invest in around this thesis.